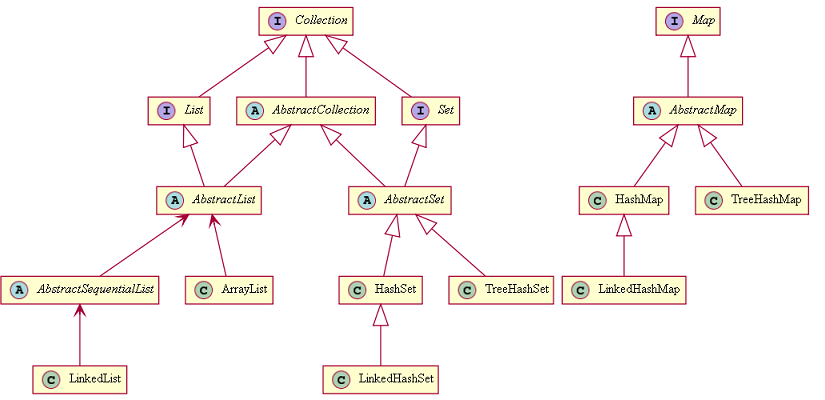
Kolekcje są strukturami danych zorientowanymi na przechowywanie obiektów. Kolekcje w Javie dzielą się na listy, mapy i zbiory. Mimo tego, że tablice także służą do przechowywania elementów, to pod nazwą kolekcje uznaje się te struktury, które implementują (pośrednio) interfejs java.util.Collection lub java.util.Map. Można zatem założyć, że kolekcje to struktury nie tylko przechowujące obiekty, ale także udostępniające mechanizmy pozwalające na wstawianie, pobieranie, przeglądanie, czy usuwanie z nich obiektów. Przejrzymy interfejsy java.util.Collection oraz java.util.Map wraz z różnicami między ich implementacjami.
Collection
– interfejs java.util.Collection – podstawowy interfejs kolekcji. Pozwala on na wykonanie podstawowych operacji na kolekcji, takich jak dodawanie do kolekcji (metody add() oraz addAll()), usuwanie z niej (remove(), removeAll(), removeIf(), ale także retainAll() i clear()), sprawdzenie rozmiaru (isEmpty(), size()), sprawdzenie czy kolekcja zawiera jeden lub więcej podanych elementów (contains(), containsAll()) oraz zamiana kolekcji na strumień (stream() oraz parallelStream()). Zawiera także metody zwracające obiety Spliterator oraz Iterator, ale o tym kiedy indziej.
Metody wstawiające obiekty zawsze zwracają typ boolean. Jest to przydatne z tego względu, że niektóre z kolekcji (np. sety) nie pozwalają na przechowywanie kilku egzemplarzy tego samego obiektu. Próba dodania po raz drugi tego samego elementu nie zakończy się wyrzuceniem wyjątku, lecz zwróci wartość false. Innymi słowy wartość zwracana przez metody wstawiające obiekty odpowiada na pytanie “czy stan kolekcji się zmienił?”.
Badanie rozmiaru kolekcji metodą size niesie za sobą pewne niebezpieczeństwo. Otóż w momencie, gdy rozmiar tablicy jest większy niż 2147483647, czyli Integer.MAX_VALUE, to metoda zwróci jedynie wartość maksymalną.
Podczas badania zawartości kolekcji (metody contains i containsAll), co istotne, nie jest sprawdzana referencja do obiektu, tylko jego metody hashCode i equals. Należy o tym pamiętać sprawdzając, czy element jest w kolekcji, albo dodając kolejne elementy do kolekcji, w której nie może być powtórzeń (jak np. Sety).
List
– interfejs java.util.List dziedziczy po Collection i dodaje kilka kolejnych metod, które odróżniają listy od kolekcji innego typu. Przede wszystkim indeks – korzystając z list można odwołać się do dowolnego elementu kolekcji, bez potrzeby iterowania po całej jej zawartości. Jest to widoczne w metodach add/addAll (wersja, w której oprócz elementu podajemy indeks, na którym powinien być umieszczony nowy element), get, czy wszelkie wariacje metody indexOf (indexOf, lastIndexOf).
ArrayList
Lista utworzona na podstawie tablicy. Wynika z tego, że lista przechowuje informacje o tym, pod jakim indeksem jest konkretny element. Powoduje to, że wyszukiwanie dowolnego elementu z listy jest stosunkowo szybkie. Lista tego typu działa w taki sposób, że inicjalnie jest tworzona tablica dziesięcioelementowa, a w przypadku dodania do listy 11-tego elementu – tablica jest powiększana o 50% (do 15 elementów). Następnie, po przekroczeniu kolejnej granicy tworzona jest znów tablica o 50% większa od poprzedniej itd. Każde powiększenie tablicy oznacza, że należy przepisać wszystkie elementy ze starej tablicy do nowej.
LinkedList
Lista utworzona na podstawie powiązań między elementami. Każdy element ma wskaźniki do poprzedniego i następnego elementu, przez co operacje dodawania lub usuwania elementów są bardzo szybkie. Dodanie elementu na początek listy powoduje jedynie, że pierwszy element istniejącej listy dostanie wskaźnik prev wskazujący na dodawany element, natomiast dodawany element od tej pory będzie wskazywał nextem na element, który dotychczas był pierwszy. Jest to duży zysk w porównaniu do implementacji ArrayList, gdzie dodanie elementu na początek listy skutkować będzie przepisaniem całej zawartości tablicy do nowej struktury. Wyszukiwanie jest natomiast w LinkedList utrudnione, gdyż, aby znaleźć dowolny element należy iterować od początku listy tak długo, aż element się znajdzie.
Set
– interfejs java.util.Set może przechowywać jedynie unikalne elementy. Będąc dokładnym – nie istnieje w Secie para elementów e1 oraz e1 taka, że e1.equals(e2), oraz maksymalnie jeden element nullowy. Nie jest możliwe zatem dodanie dwóch obiektów o różnych referencjach, które natomiast zawierają te same wartości pól, należy na to zwracać uwagę.
HashSet
Najpopularniejsza implementacja interfejsu java.util.Set. Zezwala na dodanie elementu null do zbioru, jednakże nie gwarantuje, że elementy zostaną w zbiorze w takiej samej kolejności, w jakiej były do niego dodawane. Implementacja gwarantuje stałą złożoność czasową prostych operacji (add, remove, contains oraz size), w oparciu o funkcję hashującą. Dodawanie elementu działa na zasadzie “kubeczków hashowych” – po wyliczeniu wartości funkcji skrótu, element dodawany jest do odpowiedniego kubeczka. W przypadku kolizji hashy – pod danym hashem jest kilka elementów, dla których jednak metoda .equals zwraca false. Wewnątrz “kubeczka” znajduje się tablica, po której iteruje się, aby znaleźć konkretny element. Posortowany zbiór realizuje się poprzez implementację TreeSet, a aby zapamiętać kolejność wstawiania elementów do zbioru, należy skorzystać z LinkedHashSet.
TreeSet
Implementacja java.util.Set oparta o drzewo czerwono – czarne. Oprócz unikalności elementów gwarantuje także ich uporządkowanie zgodnie z Naturalnym porządkiem (metody compareTo, klasy Object – należy stworzyć własny komparator, jeśli chcemy, by elementy były sortowane według niedomyślnej kolejności).
Map
– interfejs java.util.Map, przechowujący dane w parach klucz-wartość. Klucze muszą być unikalnyzmi wartościami, natomiast wartości mogą się powtarzać. Jeden klucz odpowiada jednej wartości. Jako zbiór kluczy powinny być wykorzystywane elementy, które nie zmienią swej wartości, gdyż zachowanie mapy jest nieznane w przypadku zmiany wartości klucza. Podstawowe metody w interfejsie to clear (czyszcząca mapę), size/isEmpty (zwracająca odpowiednio rozmiar i wartość boolowską czy mapa jest pusta), put/get (do wstawiania i pobierania elementów z mapy), remove (usuwanie), oraz trzy możliwości przeglądania map: keySet (zwraca zbiór kluczy), values (zwraca kolekcję wartości) oraz entrySet (zwraca zbiór par klucz-wartość typu Map.EntrySet). Warto dodać, że mapy są serializowane wtedy i tylko wtedy, gdy zarówno typ klucza jak i typ wartości jest serializowany.
HashMap
Najpopularniejsza implementacja interfejsu Map. Złożoność obliczeniowa wstawienia i pobrania elementu z mapy hashowej to O(1) (przy założeniu, że znany jest klucz wartości). Elementy do mapy wstawia sie metodą put(klucz,wartość), natomiast pobiera korzystając z get(klucz). Podczas wstawiania elementu, wyliczany jest hashCode klucza, przez co znalezione jest miejsce w zbiorze kluczy, gdzie powinien trafić dany klucz. Działa to podobnie jak w HashSet – na zasadzie “kubeczków” (hash buckets), gdzie znajduje się tablica z konkretnymi już kluczami (porównanie metodą equals). Podczas pobierania elementu z hashmapy, podaje się klucz, który ponownie jest przeliczany, aby dotrzeć do właściwego kubeczka. Jeśli w kubeczku jest tylko jeden klucz – element jest natychmiastowo odnajdywany. W przeciwnym wypadku, należy przeiterować po całej tablicy kluczy, aby znaleźć ten właściwy.
TreeMap
Implementacja mapy w oparciu o drzewo czerwono czarne. Dzęki temu pesymistyczna złożoność pobierania elementów z mapy jest w czasie logarytmicznym. Wstawianie elementów jest wolniejsze niż w pozostałych implementacjach mapy, ze względu na bilansowanie drzewa. Sortowanie następuje przed wyliczeniem hasha, służącego umieszczeniu klucza w odpowiednim kubeczku.
LinkedHashMap
Trzecia z implementacji, mapy, która jest pewnym kompromisem pomiedzy HashMapą a TreeMapą. Tak samo jak ta pierwsza – oferuje stałą złożoność dodawania i dostępu do danych, jednakże utrzymanie listy zajmuje więcej czasu niż utrzymanie typowej tablicy hashów. Chroni to klienta przed chaotycznym i niewyspecyfikowanym uporządkowaniem elementów w typowej HashMapie, bez narażania na koszty związane z TreeMapą. Może być wykorzystana do stworzenia kopii już uporządkowanej mapy, która zachowa kolejność oryginalnej. Służy do tego konstruktor przyjmujący implementację interfejsu java.uti.Map jako argument.
Synchronizacja kolekcji w Javie
Standardowo kolekcje są niesynchronizowane. Aby utworzyć synchronizowane kolekcje, należy skorzystać z klasy Collections, która udostępnia metody tworzące synchronizowane kolekcje (synchronizedCollection), listy (synchronizedList), mapy (synchronizedMap), zbiory (synchronizedSet) czy zbiory i mapy posortowane (synchronizedSortedMap, synchronizedSortedSet). O samej klasie Collections oraz jej metodach będzie oddzielny wpis.
“Jest to przydatne z tego względu, że niektóre z kolekcji (np. listy) nie pozwalają na przechowywanie kilku egzemplarzy tego samego obiektu.”
– list nie pozwalają na duplikaty ????
Dzięki Exoo, za zwrócenie uwagi. Chodziło oczywiście o sety.